04Oct

Shortcut Manager - RSoC Project
Shortcut Manager - RSoC Project Greetings! I’m Emad Sohail (aka PremadeS), a 2nd-year CS undergraduate...
Read More
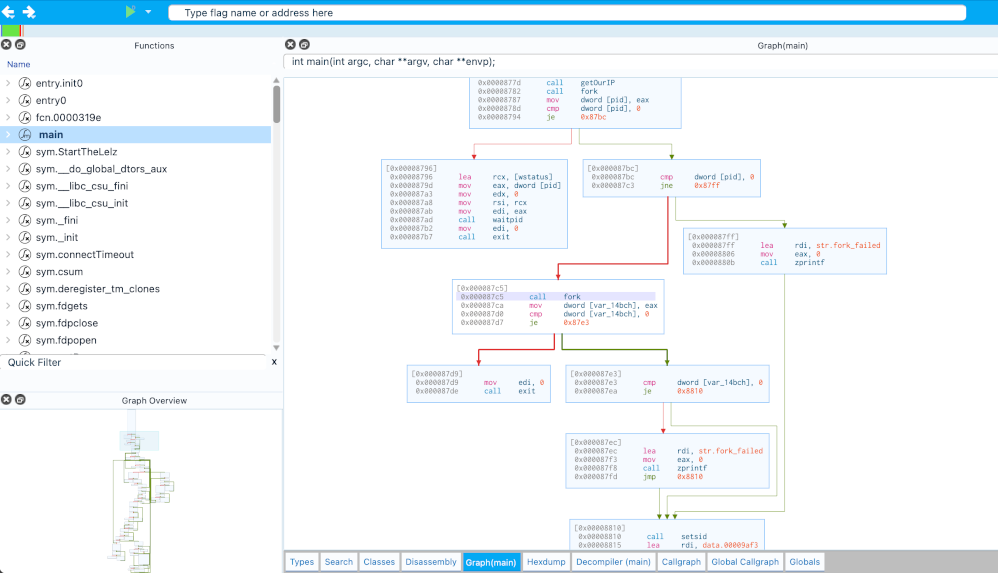


Cutter's goal is to be an advanced FREE and open-source reverse-engineering platform while keeping the user experience at mind. Cutter is created by reverse engineers for reverse engineers.

Cutter is using Rizin as its core engine. Thus, allows access to thousands of features via the GUI or by using the integrated terminal.

Cutter provides enormous amount of different widgets and features to make your Reverse Engineering experience as comfortable as possible.
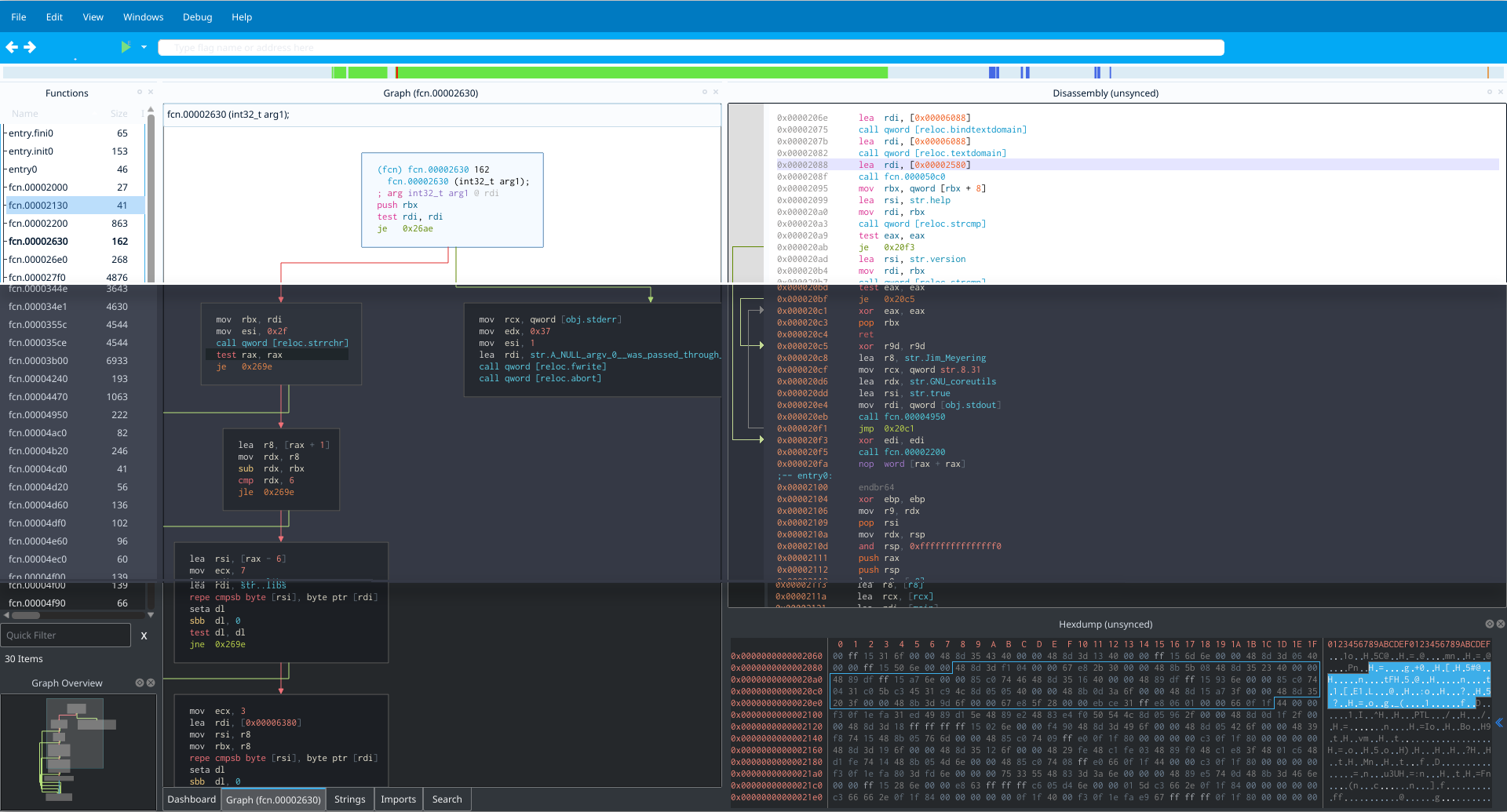
By default, Cutter is coming with multiple modern themes -- Light, Native, Dark and Midnight.
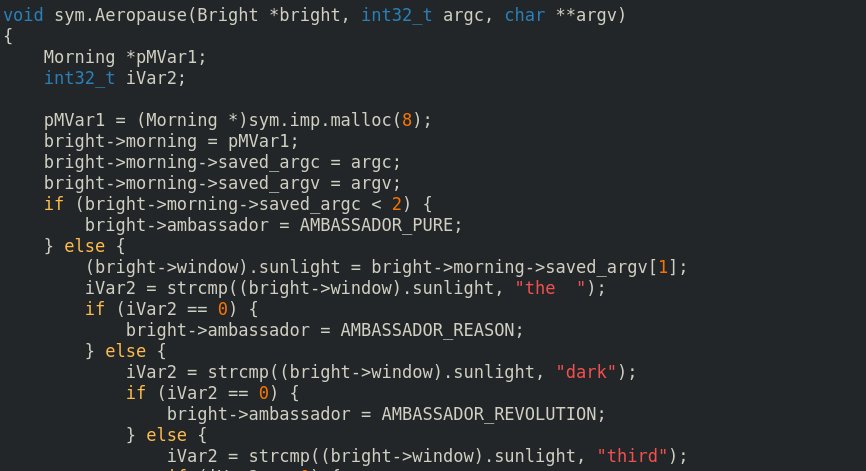
Cutter releases are fully integrated with native Ghidra decompiler. No Java involved.



Completely FREE and licensed under GPLv3
Native integration of Ghidra's decompiler in Cutter releases
Fully featured graph view as well as mini-graph for fast navigation
Multiplatform native and remote debugger for dynamic analysis
Linear disassembly view
View and modify any file with a rich and powerful Hex View
Quickly write python scripts to automate tasks
Use Native or Python plugins to extend Cutter's core functionality
Add, remove and modify bytes and instructions
Great for automation, crypto algorithms and malware analysis
Fully featured theme editor for easy and user-friendly customization of Cutter
Built using Qt C++ and design best practices

Shortcut Manager - RSoC Project Greetings! I’m Emad Sohail (aka PremadeS), a 2nd-year CS undergraduate...
Read More
As a second project of my RSoC internship, I worked on integrating the Rizin Mark...
Read MoreCutter was built as a cross-platform application so you can use it on your favorite operating system.